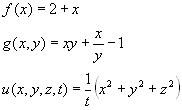
An Overview of Mathematics for the Layperson
Colin R. Mitchell
Introduction
Working in a tutoring lab for a semester, I frequently would be asked by beginning-level or non-technical students, "what is all of this math good for?" It was really hard to come up with a meaningful but succinct answer that would satisfy them. I realized that, at that level of study, the hokey examples in the book were not enough to hint at the power of mathematics. It is thus my goal of this short article to explain, in mostly non-technical terms, why the study of mathematics is important and beneficial both to everyday living and to the quest for knowledge, in general. My goal is not to bore you with tedious calculations or long and daunting equations, but I hope that you may get a general understanding of some of the important topics in mathematics.
It has been said by a friend of mine, that mathematics is the king of all the sciences. I have to agree in this. Psychology is basically biology, biology is chemistry, chemistry is physics, and physics is mathematics. Obvious or not, mathematics lies at the root of all problems. Whether we can identify it or make it useful is the problem at hand.
We will begin with basic mathematics, its uses both immediately and as building blocks for higher-level mathematics. I can in no way cover all of mathematics, or really even give most of it justice in this article (not to mention that I know so little of the great world of mathematics, even as a graduate student).
Functions
The first topics that students study include polynomials, functions, the quadratic equation, and trigonometric functions. A basic but most important part of mathematics is the idea of a function. A function is an assignment, where you put some numbers in, and get a number back. Examples of functions include
Looking at the first function, we see that f is its name, and we put one number into it, which we call x. The right side of the equation tells us what to do with that number, and after we operate, we get a single number back. You can see that we may name a function whatever we like, and put in as many numbers as we want. The numbers that we put in are called arguments.
Now that we know what a function is, we can classify them based on the definition, or what the ride side tells us to do. For example, a quadratic polynomial could look like
![]()
We call it quadratic because of the highest power of the argument, 2. We could also have cubic polynomials, where the highest power is 3, quartic polynomials with highest power four, and so on.
Sometimes, we want to find what x would make this true
![]()
If we find an x that does this, then we call x a root of the function. We will see later how these can be important. For now, we have some ways of determining what that x might be. If our function is a quadratic, cubic, or quartic, we have formula that we can use that punch out what our x’s are. It is possible for us to have as many roots that satisfy the equation as the highest order, or highest power, of the polynomial. I.e., for a quadratic, we could find one or two roots, or not find any. With a quartic, we could find one, two, or three roots, or none.
Imaginary Numbers
Now, I will introduce a branch of mathematics that seems baffling at first. You probably know that we cannot take the square root of a negative number. You may not know why, but you know that it is illegal. It is because the square root is not defined for inputting negative numbers. This is because, it is the inverse function of ![]() . That is, it cancels out
. That is, it cancels out ![]() . Here are two graphs, with
. Here are two graphs, with ![]() shown in red, and
shown in red, and ![]() shown in blue
shown in blue
It turns out that we can fix the problem of square-rooting negative numbers, if we introduce what is called the imaginary number. It is called this, because it has no meaning whatsoever in real life. You just can’t square any real number to get a negative number. But, it does allow us to carry on some calculations that we might not have before, that do yield real, useable results. We define the imaginary number, i, to be
![]()
If we consider this be a valid number, then we can computer whatever we like with a square root. For example,
![]()
Amending imaginary numbers, we can form what are called complex numbers, which we think of as just one number, but actually contain two, a real part, and an imaginary part. Thus, ![]() is a complex number, and is considered a different number than the "complex" numbers
is a complex number, and is considered a different number than the "complex" numbers ![]() and
and ![]() . We call these two complex, because we can think of the imaginary or real parts as being zero, and still classify them as such.
. We call these two complex, because we can think of the imaginary or real parts as being zero, and still classify them as such.
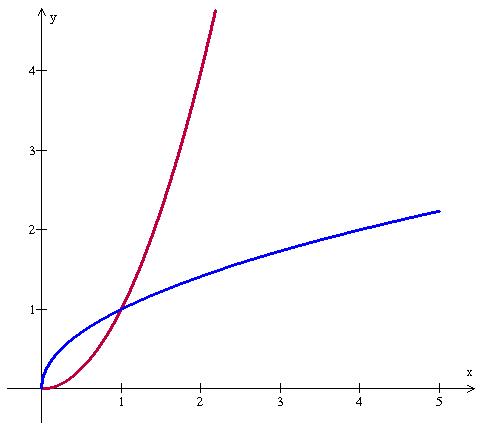
Now, you may be thinking of how numbers that have no meaning in real life could possibly be useful. It turns out that they are magnificently useful, and also very elegant. Almost every rule that we use to work with real numbers, holds just the same if we use complex numbers. That is, if we think of a unique complex number as being ![]() , where x and y are any real numbers, then we see the same rules holding for complex numbers as for reals, such as
, where x and y are any real numbers, then we see the same rules holding for complex numbers as for reals, such as
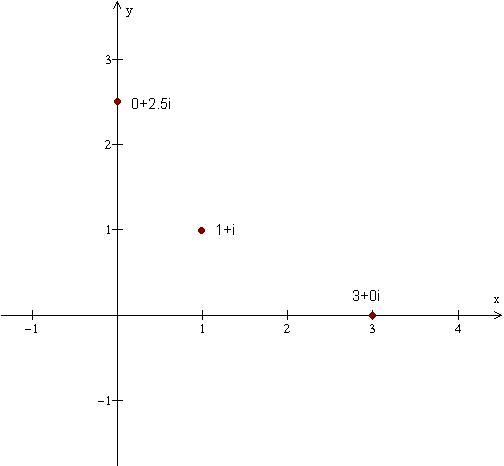
The important concept to note here is that a complex number is composed of two different numbers, which could be whatever. That is, we can pick one number, and then pick the other number to be whatever we like. We then say that a complex number is composed of two dimensions, one dimension for each number we pick. Since a complex number is made of two dimensions, we could plot it on a graph, right?
Exactly! We could plot it, where the horizontal axis represents its real part, and the vertical axis represents its imaginary part. For example, here are plots of three complex numbers
We will now leave off with complex numbers until we know some calculus, then we will return to see how powerful they are. But before we get to calculus, we should understand a little trigonometry and linear algebra.
Trigonometry
Usually, people cringe when they hear the word "trigonometry," and it is not completely unjustifiable. Working with trigonometry for several years as an undergraduate, it becomes second nature. But the ideas do get confusing at first. Trigonometry is based on triangles. Simple enough, right? Hopefully it will be.
We will define three functions, which should be adequate in our travels in this article. As you may know, these functions are sine, cosine, and tangent. Consider the following right triangle
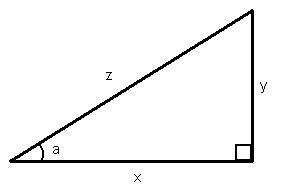
We call the longest side the hypotenuse. The trigonometric functions are defined to relate angles inside the triangle with some of its sides. Their definitions are
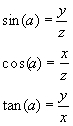
Notice that we only consider the bottom-left angle. You may remember from high-school the mnemonic "SOHCAHTOA," which stands for "sine, opposite over hypotenuse; cosine, adjacent over hypotenuse; tangent, opposite over adjacent." We call the bottom side adjacent, the right side opposite, and we already know what the hypotenuse is. We will now leave trigonometry alone. Let us move on now to linear algebra.
Linear Algebra
We use the idea of a number being a unique thing quite commonly. We discussed earlier of thinking of a complex number as being a unique thing, even though it is composed of two things, or "two dimensions." We can extend this idea further, defining what we call a vector. A vector is simply a collection of numbers, ordered in a certain way. For example, some vectors are
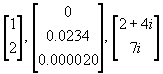 .
.
As you can see, we can have vectors with two or three items, but we could have as many items as we like. We could have a vector that can hold seven numbers, so we would say it is "7-dimensional." So any vector that has seven elements is said to belong to a 7-dimension vector space. A vector space is a purely mathematical idea, which is a "space" that contains every possible vector containing seven elements. Our universe, for example, which has four dimensions (three spatial, and one time), could then be described by a 4-dimensional vector space, where a vector would match with a position in the universe.
We can even extend vectors to form a matrix. This is similar to a vector, but it a rectangular grid of numbers. For example, some matrices are
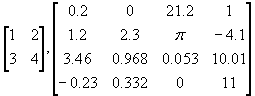 .
.
Now, we can use these two objects, a vector and a matrix, in an equation, just as if they were a number. The most important use is in linear equations, which combines the two through addition and multiplication. A common problem is find what numbers a, b, would make this equation true
![]() .
.
Here, we have a matrix being multiplied by a vector, to give back another vector. This is a common form that is used in many areas of mathematics. It is called a linear system of equations. We won’t go into the details, but know that it is used to solve equations that are simultaneous, or must be solved together, as the equations act on each other. We also call the matrix in this equation a linear operator, as it "takes one vector to another." Remember this term. Now, if we call the matrix, or linear operator, L, call the vector on the left side x, and call the vector on the right side b, we can write this in the more compact form
![]() .
.
Calculus
To those not yet familiar with calculus, it may seem like that great mystery that could never be understood. To those with experience in calculus, it seems only a natural extension of algebra. We will leave alone the complicated definitions and formula of calculus, and learn its basics through simple geometry.
Although discovered the other way around, we will learn first what a derivative is, and then what an integral is, and finally, how they are related.
Consider a function, with the following graph in red
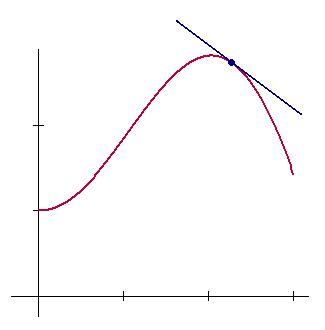
Suppose we want to look at a point on the curve, and draw a line that goes through just that point, and no others. We call this line tangent to the curve at point x (plotted in blue). We notice that the line has a slope, that it either goes up or down as we go from left to right. This slope can be represented by a number, which is how far the line goes up or down as we go a certain distance from left to right. For example, a slope of 1 means that the line moves upward at a 45°, and a slope of 0 means that is completely horizontal. A peculiar thing to notice here is that we don’t have a number to attribute to a slope of a vertical line. As our slope number gets bigger and bigger, the line it represents gets closer to becoming vertical, but never quite reaches it, no matter how big of a slope we pick. We then must say that a vertical line has a slope of infinity.
So what we mean, when we speak of "finding a derivative," is picking that point x, and trying to figure out directly what its slope is. The value of its slope is its derivative at point x. The point of calculus is to take some given function, massage it a little, and we get out another function that tells us directly the derivative at any point we want (or all of them). So if we have a function ![]() , we denote the function that is its derivative as
, we denote the function that is its derivative as ![]() , read "f prime of x." Sometimes, it is also written as
, read "f prime of x." Sometimes, it is also written as ![]() , which means exactly the same thing, and can be read as "the derivative of f with respect to x."
, which means exactly the same thing, and can be read as "the derivative of f with respect to x."
As you can probably guess, there is no reason why we could not then take the derivative of the derivative of a function. We call this the second derivative of f. And you can see that we could carry this on indefinitely (actually, sometimes we can, and sometimes we have to stop somewhere).
We saw earlier that we could have functions that have several arguments. Can we take their derivatives? Certainly! But what would this really mean? Well, think of a bowling ball in three-dimensional space. Take a Sharpie, and draw a straight line that goes all the way around the circumference of the ball to meet back where you started. Start again at your original point, but draw another line perpendicular to the first line. Now you have split the ball into four hemispheres. Find a ruler, and place it on the ball at the one of the intersections, aligning it with on of the lines you drew on the ball. If it looks like the following picture, you have just made a partial derivative!
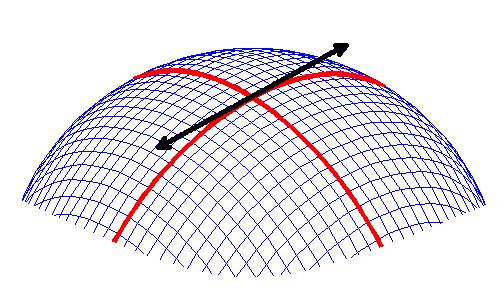
But you could also align the ruler with the other line at that intersection, right? So we see that we can have two derivatives at one point, each aligning with one of the dimensions of space (one of the arguments).
How would we write this down? It’s really quite easy. Say our function is defined as ![]() . We put in a spatial coordinate, say a point on your carpet, and the functions tells us how far to come up off of the floor. How do we write the two derivatives? Since we have two different derivatives, we can no longer just use the ‘prime’ notation. Instead, we use either the fraction notation, but with a slightly different symbol than the ‘d,’ or we use a subscript to show which argument we are differentiating with respect two
. We put in a spatial coordinate, say a point on your carpet, and the functions tells us how far to come up off of the floor. How do we write the two derivatives? Since we have two different derivatives, we can no longer just use the ‘prime’ notation. Instead, we use either the fraction notation, but with a slightly different symbol than the ‘d,’ or we use a subscript to show which argument we are differentiating with respect two
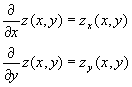
The first line is read as ‘the partial derivative of z with respect to x,’ and the second line is read as ‘the partial derivative of z with respect to y.’
And just like taking several ‘regular’ derivatives with just one argument, we can take several partial derivatives, and mix and match as we please. For example, all of the following are valid derivatives
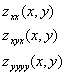
The first line is a second derivative of z with respect to x, twice. The second line is a mix, we take the derivative of z with respect to x, then y, then x again, so that we are taking a ‘third derivative’ or sorts. The third line is the ‘fourth’ derivative of z with respect to y. What a mouthful!
Now, we finally reach some applications. Usually, the first application learned after differentiation (verb for "taking the derivation") is regarding the position, speed, and acceleration of a projectile. Let’s say that we a have a function, ![]() . We put a time in seconds into it, and it tells us how far away a bullet is that we shot from a gun that we are holding. It turns out that it’s derivative,
. We put a time in seconds into it, and it tells us how far away a bullet is that we shot from a gun that we are holding. It turns out that it’s derivative, ![]() , is the speed of the bullet. So we put in a time, and the derivative tells us how fast it’s going at that time. Now, the second derivative,
, is the speed of the bullet. So we put in a time, and the derivative tells us how fast it’s going at that time. Now, the second derivative, ![]() , takes a time, and tells us how the bullet is accelerating, so we know if it is speeding up or slowing down. We will return to this a little later, where we will see that we can use physical laws to figure out what exactly
, takes a time, and tells us how the bullet is accelerating, so we know if it is speeding up or slowing down. We will return to this a little later, where we will see that we can use physical laws to figure out what exactly ![]() is if we know how fast the bullet is going.
is if we know how fast the bullet is going.
The second important concept of calculus is what we call the integral. The integral stems from another problem that had plagued early mathematicians for centuries. Given some function, how could we find the area underneath it, between two chosen points? It took some time, but someone found out that we could break the area we want to find into chunks. As the width of the chunks is reduced (and more of them added), we see that our approximation gets better and better. Take a look:
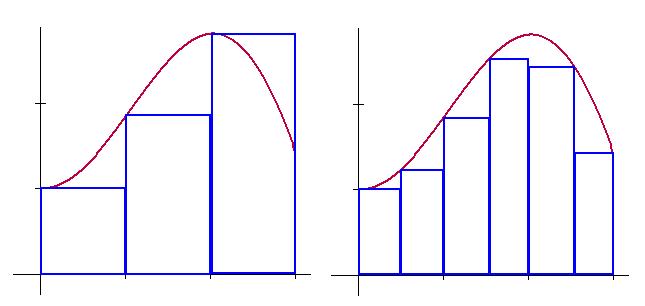
Now, here is the important part, so pay attention! The basic tool used in calculus is the limit. What this means is, take some function, and put larger and larger numbers into it. As we put in larger numbers, does the value of the function approach some constant number? That is, if we put in a big enough number, we can get as close to that constant number as we want. That number that we are trying to reach is called the limit of the function.
Some time is spent in calculus courses figuring out what functions have limits and what do not. If a function has a limit, we can figure out what it is, and we are in business. So we can take this idea of a limit, and apply it to the chunks that we used to divide up the area we want to find. We notice that as we put more chunks in, we get a number that is closer to the answer. So if we put in enough chunks, we can get as close to the answer as we want. Think about what might happen if we put in an "infinite amount of chunks?" That’s the same thing as taking the limit, as the number of chunks "goes to infinity." So the area of our chunks, as we take the limit of the numbers of chunks we use, is called the integral, and is the actual, true-and-blue area under that curve. There are direct ways, just like for a derivative, to figure out exactly what that integral is, but we won’t delve into it here. The important idea is that we know what an integral is.
So now we now derivatives, and we know integrals. And both of those problems seem a little ‘out-there,’ right? Well, to our amazement, the are inversely related. That is, one is the inverse of the other. So if we choose some function, and take it’s derivative, the integral of the derivative is the original function. And if we integrate a function, taking the derivative of that integral is the original function. This connection between the two is called the fundamental theorem of calculus.
Let’s apply this to our bullet problem earlier. We have a gun, and a bullet, and we know the speed of the bullet when it leaves our gun (it says so on the box of bullets that we bought!). We start with Newton’s law of motion,
![]()
Remember that acceleration was the second derivative of the bullet’s position? We can use Newton’s law, along with how much our bullet weighs, to write down the second derivative, ![]() . Then, if we integrate that function twice, we have our position function
. Then, if we integrate that function twice, we have our position function ![]() , so now we know how far away the bullet is at time t!
, so now we know how far away the bullet is at time t!
Calculus has many uses in physics, but did you know that it has uses in business, economics, statistics, astronomy, and chemistry? Derivatives can be used to figure out how to price an item just right for maximum profit, based on the market demand. Calculus can also be used to figure out how many bad products are produced in an assembly line. Calculus is even used to try to figure out exactly what is happening inside of a black hole. But this is just the beginning.
Differential Equations
Now that we know what calculus actually does, we can begin to use it. Probably the most commonly-practiced field of calculus, many applications, products and processes come from the use of differential equations. A differential equation is simply an equation that contains derivatives of a function. The problem at hand is, what function satisfies the equation? As an example, consider the differential equation
![]()
What function, or functions, could we put in for ![]() so that the equation is true? Sometimes, if we’re good, we can just look at it and know. Sometimes, we need to use some methods and some mathmagic to figure out what will work. And other times, we can’t write down an answer, and we must use a computer to figure out the answer for us. Here, we see a split. This takes us into two fields of mathematical study, analytic, where we find the answer directly on paper, and can express it in symbols. The other field, we call numerical, is where we write computer programs that use the differential equation to approximate the answer. Since the answer cannot be written out in symbols, we use the data in the computer as the answer.
so that the equation is true? Sometimes, if we’re good, we can just look at it and know. Sometimes, we need to use some methods and some mathmagic to figure out what will work. And other times, we can’t write down an answer, and we must use a computer to figure out the answer for us. Here, we see a split. This takes us into two fields of mathematical study, analytic, where we find the answer directly on paper, and can express it in symbols. The other field, we call numerical, is where we write computer programs that use the differential equation to approximate the answer. Since the answer cannot be written out in symbols, we use the data in the computer as the answer.
One very important tool that we can use on these differential equations is called the Fredholm Alternative Theorem. Remember how we talked about vectors? Well, it is advantageous to think of a function, such as the one we want to find, as a vector, which has infinite dimensions. We can then think of a differential equations as being linear equation, just like with matrices and vectors. Think of ![]() as one vector, and the right side of the above equation, 0, as another vector. But what is the matrix, then? We called earlier the matrix a linear operator. It turns out that we can also think of the left hand side as some kind of operator acting on
as one vector, and the right side of the above equation, 0, as another vector. But what is the matrix, then? We called earlier the matrix a linear operator. It turns out that we can also think of the left hand side as some kind of operator acting on ![]() , doing funny things with it and its derivatives. These funny things are linear. So what is the ‘operator’ part? We can write the operator as
, doing funny things with it and its derivatives. These funny things are linear. So what is the ‘operator’ part? We can write the operator as
![]()
where the fractions represent "taking the first or second derivative of." So when the operator "acts" on ![]() , we get the left side of our original equation. You can then see that we can write our differential equation in a shorter form,
, we get the left side of our original equation. You can then see that we can write our differential equation in a shorter form,
![]()
Looks just like a linear equation! So what the Fredholm Theorem does is it tells us if the differential equation has a solution or not, and if it has just one solution, or infinitely many. It does this by seeing if the right side, in this case 0, is in the range of the operator, or if the operator can actually turn ![]() into 0. Pretty slick, huh?
into 0. Pretty slick, huh?
The differential equations we just looked at are called ordinary differential equations (ODEs). These equations contain a function that has only one argument. But we can have functions that have more than one argument. So shouldn’t we also be able to have differential equations based on these functions? But, of course! Suppose we have some function that is dependent on a position in space, and a time, ![]() . Then we could have a differential equations that combines some derivatives of it. That would be called a partial differential equation. These can sometimes get messy and complicated, and commonly must be solved using numerical methods. But they also cover a wide range of applications.
. Then we could have a differential equations that combines some derivatives of it. That would be called a partial differential equation. These can sometimes get messy and complicated, and commonly must be solved using numerical methods. But they also cover a wide range of applications.
Differential equations can come from many different problems. For example, think of a one-dimensional wire in our lab, that’s sitting at room temperature, suspended by insulated braces, and is six feet long. Suppose we heat one end with a propane torch. What’s the temperature at the other end after two minutes? 5 minutes? What would the temperature at the end approach as we sat there for days or weeks or months? We can use laws of heat transfer, which are based on derivatives, to form a partial differential equation. We know that the propane torch would produce a pretty steady heat on the end of the wire, so it would form a source at that end of the wire. Suppose the wire is wrapped in insulation, so that heat could only escape out of the other end of the wire, where we would have a flux. We might know how the heat would move through the wire based on the thermal conductivity of the material the wire is made of. So how do we wrap this all together and answer our questions?
We would first derive our PDE (partial differential equation) and reach something like
![]()
where D is our coefficient of thermal conductivity (based on what the wire is made of). But we need to say something about the ends of the wire, and what the temperature of the wire is like when we begin our experiment. We would call these the boundary conditions and initial condition, respectively. Say the propane torch heats the one end of the wire at 1200°F, and the other end can emit heat into the room. Also, the wire is at room temperature when we start, so the entire wire is at 68°F. So we can write the initial condition as
![]()
which means that at time ![]() , the temperature across the entire rod (all values of x) is 68. The left boundary condition would be
, the temperature across the entire rod (all values of x) is 68. The left boundary condition would be
![]()
which means that at the left end of the rod (![]() ), the temperature is always 1200, regardless of time. The right boundary condition is a little bit trickier. If the temperature of the rod is higher than the temperature of the air, then heat is going to want to transfer from the wire to the air. There is a law that describes this, called Fourier’s Law, so we use to it write this boundary condition as
), the temperature is always 1200, regardless of time. The right boundary condition is a little bit trickier. If the temperature of the rod is higher than the temperature of the air, then heat is going to want to transfer from the wire to the air. There is a law that describes this, called Fourier’s Law, so we use to it write this boundary condition as
![]()
Think of it as this way: the derivative means "the change in temperature." So if the temperature of the wire is higher than the temperature of the air, the right side of the equation is negative, which means the change in temperature is negative, or cooling. So heat will be leaving the wire at that end.
We may be able to solve this analytically, but we could use a computer to solve it numerically, and tell use the temperature at the end of the wire at any time we like. Doesn’t sound very useful, you? It would probably just be a lot easier to heat the wire, and then measure the temperature of the end of the wire after a couple of minutes. I agree with you. But what about the heat on the surface of a martian lander as it descends to the landscape of Mars? How do we know if the lander will hold up or not? It would be pretty expensive to keep sending landers until something finally worked, right? So we have reached one of the most important uses of mathematics, that of prediction. Using all sorts of different laws and rules of physics, the ceiling of man’s creativity and ingenuity is only limited by his motivation. Let’s consider a few other topics of mathematical prediction.
Prediction
As we have seen, the real power of mathematics lies in knowing what is going to happen before it happens. I’m sure that you have heard of the massive particle accelerators that are built in hopes of completely understanding the quantum world (the world of the smallest particles known to man). Did you know that through mathematics and a little experimentation, we have found particles smaller than an electron? Did you know that, because a certain quantum equation had both positive and negative solutions, we were able to discover antimatter, matter that is an opposite, mirror image of the protons, electrons and neutrons that comprise our world?
Through mathematics and a little statistics, did you also know that if the ratio of matter in our universe had differed by 1 part in 10000000000000, our universe would not have the well-formed stars, planets, galaxies or heavy metals? Or that if the ratio of matter to antimatter in the Big Bang had been similarly off, our universe would have hardly any matter, just energy?
How about that one famous guy, Albert Einstein? He came up with all of his theories just by using his mind. He had no way to experiment with objects moving close to the speed of light. He used thought experiments, to write equations which explained time dilation, spatial warping, black holes, and more. And his equations are used today to study and predict objects and events in the universe.
Other laws, such as Kepler’s laws of gravitational orbit, allow us to land a probe on Mars, to a send one into a stable orbit around Venus or Saturn. Can you recognize the amount of precision it would take to perform such a task? It has been said that trying to land a probe on Mars would be like shooting an arrow into the air from Los Angeles, and getting it to hit home plate at Wrigley Field, in Chicago. But remember, NASA only gets on chance, and doesn’t have a quiver full of space probes! Using Kepler’s laws, scientists must predict how long it would take the probe to get there, use the position of the earth at launch, predict where Mars will be (and must be exact with it), know during what time of the orbits the planets are in a prime relation, and hope that nothing goes wrong along the way.
We can use something called tensor analysis, which uses matrices, vectors, and calculus, to see how irregularly shaped objects rotate and orbit in space, and figure out where the axis of rotation will be. We can use mathematics to design and build the tiniest electronic devices, such as resistors, capacitors, and transistors. We can use number theory to figure out the most efficient way to send cell-phone calls, text messages, pictures, emails, and more. We can use calculus on complex numbers to see how fluids will flow through tubes, bottlenecks, fittings, hydraulic machines, and more. We can use partial differential equations to see how traffic flows, such as through intersections, highways, or construction areas. We can use mathematics to... Well, you get the point.